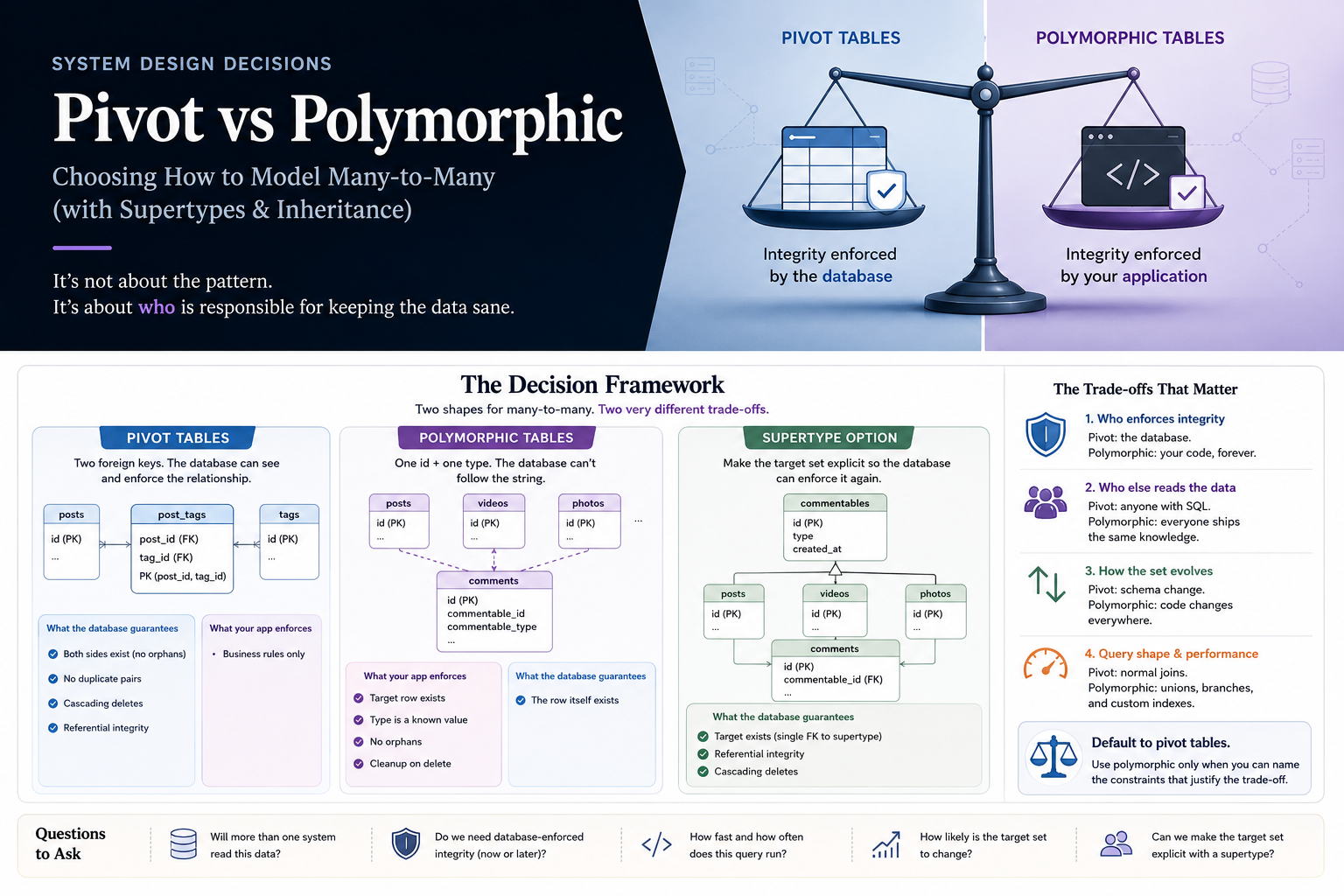
TL;DR
Two common shapes for "many of A to many of B (and maybe C, D, E)": a pivot table the database understands, or a polymorphic relationship only your application understands. The interesting thing isn't the shapes, it's the trade-off. Pivot tables move work into the database, polymorphic relationships move it into your code, and a service boundary can hide the choice from neighbours but never makes it go away. This post is a decision framework, not a tutorial. It tells you which trade-offs matter, which questions to ask, and how to write the choice down so it survives the next person on the codebase.
Why I'm writing this
Trade-offs are the quiet backbone of software development. One of the more memorable ones, for me, started as a conversation about pivot vs polymorphic relationships for many-to-many.
The codebase already had a polymorphic addresses table that attached to properties, contacts, and tenants. A colleague suggested switching to pivot tables: better control over the data, and a cleaner shape for the analytics app that was about to start reading from the database with read-only access. That's the conversation this post tries to write down.
The decision, in one sentence
So let me state the decision clearly before we look at any code. When you reach for a many-to-many relationship, you're not picking between two equally good options. You're picking who is responsible for keeping the data sane: the database engine or the application code that talks to it.
That's the whole decision. Everything else (indexes, ORM ergonomics, storage size) follows from it.
PIVOT POLYMORPHIC
┌──────────────────────┐ ┌──────────────────────┐
enforced by │ both FKs resolve │ │ the row exists │
the database ───────► │ no orphan children │ │ │
(free, automatic) │ no duplicate pairs │ │ │
│ cascading deletes │ │ │
└──────────────────────┘ └──────────────────────┘
══════════════════════════════════════════════════════════════════════════════════ DB BOUNDARY
┌──────────────────────┐ ┌──────────────────────┐
enforced by │ business rules, if │ │ target row exists │
your app ───────────► │ any (what counts as │ │ type column is valid │
(manual, every │ a valid pair) │ │ no orphans on delete │
code path, │ │ │ cleanup across types │
every consumer) │ │ │ │
└──────────────────────┘ └──────────────────────┘
Same axis on both sides: above the line is what the database enforces for you, below the line is what you have to enforce yourself. The pivot side is top-heavy by design; the polymorphic side is bottom-heavy by construction. That asymmetry is the whole point of the picture, and it is what Bill Karwin was pointing at when he wrote the book that put this debate on most engineers' shelves:
"A polymorphic association is one that can reference one of several parents. There's no way for the database to enforce referential integrity on a polymorphic association." Bill Karwin, SQL Antipatterns (Pragmatic Bookshelf, 2010)
Karwin lists it under anti-patterns. That's a strong word, and I think it's worth being precise about how strong. My version is a half-step softer:
Polymorphic associations are an anti-pattern by default. They become a deliberate trade-off only when you can name the constraints that justify them.
"By default" is doing the work in that sentence. It means: when someone reaches for the polymorphic shape in a design review, the burden of proof is on them, not on the pivot. The pivot keeps a guarantee the database was already willing to give you for free; the polymorphic shape gives that guarantee up. You can give it up on purpose, but you have to know you did.
With that bias on the table, let's look at what each shape actually looks like on disk, so the rest of the article has something to point at.
The two shapes, briefly
Two shapes, side by side:
PIVOT POLYMORPHIC
───── ───────────
┌─────────┐ ┌──────────┐ ┌──────────┐ ┌─────────┐
│ posts │ │properties│ │ contacts │ │ tenants │
│ id PK │◄──┐ │ id PK │ │ id PK │ │ id PK │
└─────────┘ │ └──────────┘ └──────────┘ └─────────┘
│ FK ▲ ▲ ▲
┌────────────┴──────┐ │ │ │
│ post_tags │ └────────────┼────────────┘
│ post_id FK │ │ ??? (no FK possible)
│ tag_id FK │ ┌────────┴──────────┐
│ PK(post_id, │ │ addresses │
│ tag_id) │ │ id PK │
└────────────┬──────┘ │ addressable_id │
│ FK │ addressable_type │
┌─────────┐ │ │ ('property'| │
│ tags │◄──┘ │ 'contact'| │
│ id PK │ │ 'tenant') │
└─────────┘ └───────────────────┘
A pivot has two foreign keys to two known tables. A polymorphic table has one integer and a string that names the target table; the database can't follow the string.
The smallest possible SQL, for context. The pivot is uneventful:
CREATE TABLE post_tags (
post_id BIGINT NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
tag_id BIGINT NOT NULL REFERENCES tags(id) ON DELETE CASCADE,
PRIMARY KEY (post_id, tag_id)
);
INSERT INTO post_tags (post_id, tag_id) VALUES (42, 7)
ON CONFLICT DO NOTHING;
SELECT p.id, p.title
FROM posts p
JOIN post_tags pt ON pt.post_id = p.id
JOIN tags t ON t.id = pt.tag_id
WHERE t.name = 'databases';
Two foreign keys, a composite primary key, a normal join. The database enforces everything that matters.
The polymorphic version looks fine until you read it:
CREATE TABLE addresses (
id BIGSERIAL PRIMARY KEY,
line1 TEXT NOT NULL,
city TEXT NOT NULL,
addressable_id BIGINT NOT NULL,
addressable_type TEXT NOT NULL -- 'property' | 'contact' | 'tenant'
);
CREATE INDEX ON addresses (addressable_type, addressable_id);
-- nothing stops this from succeeding:
INSERT INTO addresses (line1, city, addressable_id, addressable_type)
VALUES ('1 Main St', 'Berlin', 99999, 'propery'); -- typo, orphan, both
No REFERENCES. There cannot be one: addressable_id could point at properties.id or contacts.id depending on a string. Reading the target is now a branch:
-- you have to pick the table from the type column, per row:
SELECT a.line1 FROM addresses a JOIN properties p ON p.id = a.addressable_id
WHERE a.addressable_type = 'property';
SELECT a.line1 FROM addresses a JOIN contacts c ON c.id = a.addressable_id
WHERE a.addressable_type = 'contact';
-- want all of them in one query? you UNION ALL them.
Every consumer of the table now ships that branching. Add a target, edit every consumer.
That last sentence is where the conversation usually turns. "Add a target, edit every consumer" sounds small, until you realise it's one example of a wider pattern: every nice property a pivot gives you for free, you have to keep paying for by hand with a polymorphic table. Let's name those properties.
The four trade-offs that matter
Most comparison posts hand you ten criteria. In practice four of them drive the decision and the rest follow from those four. Here they are.
1. Who enforces integrity. Pivot: the database. Polymorphic: every code path that writes to the table, forever. This is the trade-off, and the rest of the list is downstream of it.
2. Who else reads the data. Pivot: anyone who speaks SQL gets a normal join. Polymorphic: every consumer (warehouse, search index, sibling service) has to know how to interpret the type column. If you have more than one consumer, or you might in a year, that string column is now a private protocol you're maintaining.
3. How the schema evolves. Pivot: a new relationship is a new table, the migration documents it. Polymorphic: a new target is a new value in a string column, the migration says nothing, every reader silently goes out of date.
4. What metadata the relationship can carry. Pivot: just add columns (added_at, added_by, weight). The relationship is a first-class entity. Polymorphic: any metadata you add applies to every target type, even when it doesn't make sense for some of them.
The other things people argue about (storage, indexing, ORM one-liners) are real but secondary. They never decide the call by themselves.
Two nuances worth naming
Before we collapse the trade-offs into a decision, two things deserve to be said out loud, because both quietly change how dangerous the polymorphic shape really is in practice.
The framework is doing the enforcing, not you. When people say "polymorphic is fine, we've used it for years and never had an orphan", they're usually right because they never left the framework. Rails' belongs_to :addressable, polymorphic: true, Laravel's morphTo()(that is the case in our company), Django's GenericForeignKey all wrap the type column with destroy callbacks, cascading deletes, and validations that fire on every write. So as long as every writer goes through the ORM, the integrity story holds up. The cost shows up the day you don't go through the ORM. A second service in a different language touches the table directly. A nightly job in Python populates rows that Rails normally created. The org migrates from Laravel to Go and the new code has no equivalent of morphTo() to lean on. At that moment every implicit guarantee the framework was carrying becomes an explicit job for someone to redo, and the schema itself gives no hint about what those guarantees were. The pivot doesn't have this problem because the guarantees were never in the framework; they were in the table.
Soft deletes change the math. If your application never issues a DELETE, only sets deleted_at, the most common way polymorphic rows go orphan (parent disappears, child is left pointing at a ghost) effectively can't happen. The parent row is still there, just flagged. Queries that respect deleted_at skip it; queries that don't, find it. Either way the referenced id resolves to a real row. That's a genuine reason teams get away with polymorphic for a long time, and worth knowing about. It is also not free: soft deletes have their own well-documented problems (every query needs to filter, unique constraints get awkward, GDPR requires a real DELETE eventually), and they only paper over the orphan-on-delete case. They don't help with typo'd type columns, target tables that genuinely get dropped, or the migration-to-another-language scenario above.
Neither of these nuances flips the decision. They tell you how much latent risk you're carrying. A polymorphic table inside a framework-locked, soft-delete-only app is low-risk in practice. The same table inside a polyglot, multi-consumer system with hard deletes is a bug waiting to be noticed.
The decision framework
Four trade-offs and two nuances is still a lot to hold in your head in the middle of a design review. So let's collapse them into the smallest set of yes/no questions that actually changes the answer.
Three questions. Answer them, then look at the table.
- Is the set of target types known and small? ("Tags and posts" → yes. "Addresses on anything that has one" → no.)
- Will anything beyond this one application read these rows? (BI tool, warehouse, search index, sibling service.)
- Will you need to query across target types for business logic? ("Show me everything tagged X, regardless of type" → yes. "Just stream me the activity feed" → no.)
Q1 known types? Q2 other readers? Q3 cross-type queries? → Pick
─────────────── ───────────────── ────────────────────── ────
yes yes yes pivot
yes yes no pivot
yes no any pivot
no yes any pivot + supertype
no no yes pivot + supertype
no no no polymorphic OK
There is exactly one row where polymorphic is the right call. That's not bias, that's how the trade-off shakes out.
You'll notice two rows in the middle land on "pivot + supertype" rather than a clean pivot. That's the shape my colleague's addresses table actually wanted, and it's the one most teams underuse, so it deserves its own section.
The escape hatch: supertype/subtype
When you genuinely need polymorphism but you also need integrity, model the commonality as a real table:
┌─────────────────────────────┐
│ addressables │
│ id BIGINT PK │ ← the real,
│ kind TEXT NOT NULL │ referenceable id
│ CHECK kind IN │
│ ('property', │
│ 'contact', │
│ 'tenant') │
└──────────────┬──────────────┘
│
┌───────────────────────┼───────────────────────┐
│ FK (1:1) │ FK (1:1) │ FK (1:1)
│ properties.id │ contacts.id │ tenants.id
│ REFERENCES │ REFERENCES │ REFERENCES
│ addressables(id) │ addressables(id) │ addressables(id)
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ properties │ │ contacts │ │ tenants │
│ id PK/FK │ │ id PK/FK │ │ id PK/FK │
│ name │ │ full_name │ │ full_name │
│ owner_id │ │ email │ │ lease_id │
└─────────────┘ └─────────────┘ └─────────────┘
┌─────────────────────────────┐
│ addresses │
│ id BIGINT PK │
│ line1 TEXT │
│ city TEXT │
│ addressable_id BIGINT │──┐
│ REFERENCES │ │ real FK to
│ addressables(id) │ │ addressables.id
└─────────────────────────────┘ │
▼
(always resolves to a row
in addressables, which
points to exactly one of
properties / contacts /
tenants)
Addresses reference addressables.id as a normal foreign key. The database keeps its guarantee. The polymorphism lives in the parent table, where the database can also keep track of which subtype each row is.
This is more setup. It is also the only shape that gives you "many target types" and "the database keeps you honest" at the same time. Reach for it when question 1 is "no" but questions 2 or 3 are "yes".
So now we have three shapes (pivot, supertype, raw polymorphic) and three questions to pick between them. Time to run the framework on real situations to see if it survives contact with reality.
Worked examples
Three cases I keep seeing in code reviews.
Tags on posts. Q1 yes, Q2 yes (search index reads them), Q3 yes (find posts by tag). → Pivot. The boring win.
Addresses on properties, contacts, tenants. Q1 yes today, maybe no tomorrow (next quarter someone wants to attach an address to a vendor). Q2 likely yes (CRM, invoicing, geocoding pipeline). Q3 sometimes (find every entity within a postcode, regardless of type). → Pivot per type, or supertype if the list grows. Three tables (property_addresses, contact_addresses, tenant_addresses) is fine. It looks repetitive; it queries cleanly.
Activity feed / audit log. Q1 no (every entity is in scope), Q2 no (only the app reads it), Q3 no (it's a stream you display). → Polymorphic is fine. This is the canonical case where the pattern earns its keep.
Notice that "addresses" isn't the slam-dunk polymorphic case people might assume. Most address tables should be pivots or supertypes; the framework tells you why.
One thing I've glossed over so far is the database itself. The framework gives you a shape; the engine you're running on decides how cleanly that shape is enforced. For most teams this doesn't change the call, but there are a handful of footguns worth knowing about before you ship.
How the major databases affect the call
The patterns are SQL, so they exist everywhere. What changes is how much help you get. Quick reference, not a deep dive:
Pivot tables Supertype pattern Polymorphic
(recommended) (when polymorphism (no FK, app-only)
is truly needed)
──────────────────────────────── ──────────────────────────────── ────────────────────────────────
PostgreSQL full FK, PK composite, table inheritance, or a parent CHECK constraint on the type
deferrable constraints table with a FK from each column + triggers to verify
subtype the referenced id
MySQL / InnoDB full FK, PK composite, parent supertype table, child triggers (clunky), no native
cascading deletes rows FK to parent.id inheritance support
SQL Server full FK, PK composite parent supertype table, child CHECK on the type column, the
(watch out for multiple rows FK to parent.id id reference stays unenforced
cascade paths)
Oracle full FK with deferrable parent supertype table, child triggers, or object-relational
constraints, no native rows FK to parent.id features if the team uses them
ON UPDATE CASCADE
SQLite full FK only if PRAGMA parent supertype table, child TEXT column + CHECK list,
foreign_keys = ON, rows FK to parent.id nothing enforces the id
PK composite
Two gotchas worth keeping in your head while you decide:
- SQL Server disallows multiple cascade paths to the same table. If two pivot tables both cascade-delete into a shared child, you'll have to break one with
NO ACTIONand handle it in a trigger. - SQLite has foreign keys off by default. You need
PRAGMA foreign_keys = ON;per connection, or your "pivot" silently behaves like a polymorphic table without the type column.
Everything else is uniform enough that it shouldn't change your decision. If the framework above said pivot, every one of these engines supports it well.
That leaves one piece of the story. We've gone from "what's the decision", through "what shapes are available", "what trade-offs they imply", "how to choose", and "what the engine helps with". The last piece is making sure the choice doesn't quietly evaporate the moment you merge.
Write it down
Whatever you pick, the decision outlives you on this codebase. Capture it in an ADR with three lines:
- The relationship and the shape you chose.
- The answers to the three questions, as of today.
- The condition under which you'd revisit it.
That third line is the one that matters. "We chose polymorphic because there's only one consumer; revisit if a second service needs these rows" is the difference between a deliberate trade-off and a future incident.
Conclusion
Back to the conversation I started with. We ran the three questions on my colleague's addresses table: target types weren't really open-ended, a second service (the invoicing pipeline) was already planning to read the rows, and yes, they did want cross-type queries (every entity in a given postcode, regardless of whether it was a property, contact, or tenant). So the answer was a supertype addressables parent plus a real foreign key from addresses. Not the pivot they expected when they walked in, and not the polymorphic they had. The middle option that nobody had named yet.
That's the part I want you to take away. Many-to-many looks like a stylistic choice and turns load-bearing a year later. The actual decision is who enforces integrity: the database, or every line of code that ever touches the table. Pivots put it in the database, which is where indexes, constraints and every SQL tool already live. Polymorphic relationships put it in your code, which is fine when you can defend the trade-off and painful when you can't.
Run the three questions. Take the boring win when you can. Reach for supertype when you need polymorphism with guarantees. Reserve raw polymorphic for the narrow case where it actually fits. And write down why, so the next conversation about this table is shorter than the one I had last week.
References
- Bill Karwin, SQL Antipatterns: Avoiding the Pitfalls of Database Programming, Pragmatic Bookshelf, 2010. Chapter on Polymorphic Associations.
- Martin Fowler, Patterns of Enterprise Application Architecture, see Association Table Mapping and Single Table Inheritance.
- PostgreSQL documentation, Foreign Keys and Inheritance.
- MySQL documentation, FOREIGN KEY Constraints.
- Microsoft Learn, Foreign Key Constraints.
- Oracle Database Concepts, Integrity Constraints.
- SQLite documentation, Foreign Key Support.